A data store hosted by a single server may be subject to the following limitations:
Scaling vertically by adding more disk capacity, processing power, memory, and network connections may postpone the effects of some of these limitations, but it is likely to be only a temporary solution. A commercial cloud application capable of supporting large numbers of users and high volumes of data must be able to scale almost indefinitely, so vertical scaling is not necessarily the best solution.
Divide the data store into horizontal partitions or shards. Each shard has the same schema, but holds its own distinct subset of the data. A shard is a data store in its own right (it can contain the data for many entities of different types), running on a server acting as a storage node.
This pattern offers the following benefits:
When dividing a data store up into shards, decide which data should be placed in each shard. A shard typically contains items that fall within a specified range determined by one or more attributes of the data. These attributes form the shard key (sometimes referred to as the partition key). The shard key should be static. It should not be based on data that might change.
Sharding physically organizes the data. When an application stores and retrieves data, the sharding logic directs the application to the appropriate shard. This sharding logic may be implemented as part of the data access code in the application, or it could be implemented by the data storage system if it transparently supports sharding.
Abstracting the physical location of the data in the sharding logic provides a high level of control over which shards contain which data, and enables data to migrate between shards without reworking the business logic of an application should the data in the shards need to be redistributed later (for example, if the shards become unbalanced). The tradeoff is the additional data access overhead required in determining the location of each data item as it is retrieved.
To ensure optimal performance and scalability, it is important to split the data in a way that is appropriate for the types of queries the application performs. In many cases, it is unlikely that the sharding scheme will exactly match the requirements of every query. For example, in a multi-tenant system an application may need to retrieve tenant data by using the tenant ID, but it may also need to look up this data based on some other attribute such as the tenant’s name or location. To handle these situations, implement a sharding strategy with a shard key that supports the most commonly performed queries.
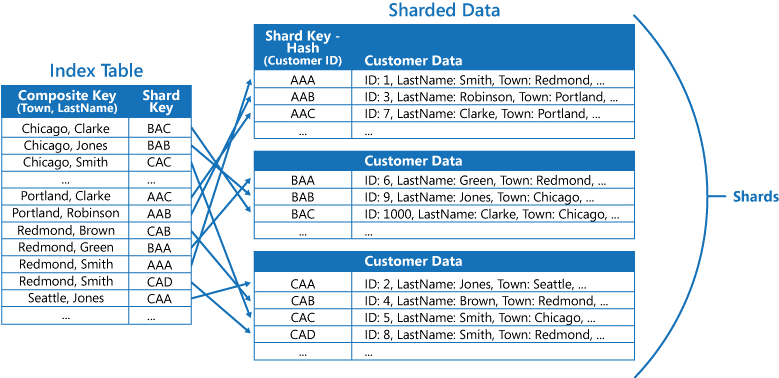
If queries regularly retrieve data by using a combination of attribute values, it may be possible to define a composite shard key by concatenating attributes together. Alternatively, use a pattern such as Index Table to provide fast lookup to data based on attributes that are not covered by the shard key.
Three strategies are commonly used when selecting the shard key and deciding how to distribute data across shards. Note that there does not have to be a one-to-one correspondence between shards and the servers that host them—a single server can host multiple shards. The strategies are:
Sharding tenant data based on tenant IDs
The mapping between the shard key and the physical storage may be based on physical shards where each shard key maps to a physical partition. Alternatively, a technique that provides more flexibility when rebalancing shards is to use a virtual partitioning approach where shard keys map to the same number of virtual shards, which in turn map to fewer physical partitions. In this approach, an application locates data by using a shard key that refers to a virtual shard, and the system transparently maps virtual shards to physical partitions.
Use this pattern:
 Systems
Systems