Many data stores organize the data for a collection of entities by using the primary key. An application can use this key to locate and retrieve data. Below shows an example of a data store holding customer information. The primary key is the Customer ID.
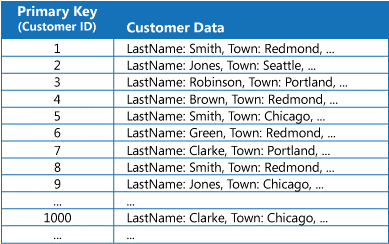
Customer information organized by the primary key (Customer ID)
While the primary key is valuable for queries that fetch data based on the value of this key, an application might not be able to use the primary key if it needs to retrieve data based on some other field. In the Customers example, an application cannot use the Customer ID primary key to retrieve customers if it queries data solely by specifying criteria that reference the value of some other attribute, such as the town in which the customer is located. To perform a query such as this may require the application to fetch and examine every customer record, and this could be a slow process.
Many relational database management systems support secondary indexes. A secondary index is a separate data structure that is organized by one or more non-primary (secondary) key fields, and it indicates where the data for each indexed value is stored. The items in a secondary index are typically sorted by the value of the secondary keys to enable fast lookup of data. These indexes are usually maintained automatically by the database management system.
You can create as many secondary indexes as are required to support the different queries that your application performs. For example, in a Customers table in a relational database where the customer ID is the primary key, it may be beneficial to add a secondary index over the town field if the application frequently looks up customers by the town in which they reside.
However, although secondary indexes are a common feature of relational systems, most NoSQL data stores used by cloud applications do not provide an equivalent feature.
If the data store does not support secondary indexes, you can emulate them manually by creating your own index tables. An index table organizes the data by a specified key. Three strategies are commonly used for structuring an index table, depending on the number of secondary indexes that are required and the nature of the queries that an application performs:
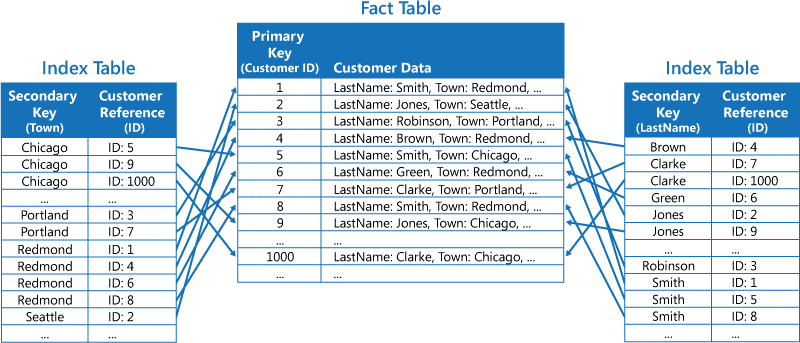
Index tables implementing secondary indexes for customer data. The data is duplicated in each index table.
This strategy may be appropriate if the data is relatively static compared to the number of times it is queried by using each key. If the data is more dynamic, the processing overhead of maintaining each index table may become too great for this approach to be useful. Additionally, if the volume of data is very large, the amount of space required to store the duplicate data will be significant.
Use this pattern to improve query performance when an application frequently needs to retrieve data by using a key other than the primary (or shard) key.
This pattern might not be suitable when:
 Systems
Systems