Akka.Net implementation pattern for high-level retry logic for major fails (Long-lasting)
An application performs tasks that comprise a number of steps, some of which may invoke remote services or access remote resources. The individual steps may be independent of each other, but they are orchestrated by the application logic that implements the task.
Whenever possible, the application should ensure that the task runs to completion and resolve any failures that might occur when accessing remote services or resources. These failures could occur for a variety of reasons.
For example, the network might be down, communications could be interrupted, a remote service may be unresponsive or in an unstable state, or a remote resource might be temporarily inaccessible—perhaps due to resource constraints. In many cases these failures may be transient and can be handled by using the Retry Pattern.
If the application detects a more permanent fault from which it cannot easily recover, it must be able to restore the system to a consistent state and ensure integrity of the entire end-to-end operation.
The Scheduler Agent Supervisor pattern defines the following actors. These actors orchestrate the steps (individual items of work) to be performed as part of the task (the overall process):
The Scheduler maintains information about the progress of the task and the state of each step in a durable data store, referred to as the State Store. The Supervisor can use this information to help determine whether a step has failed. The below illustrates the relationship between the Scheduler, the Agents, the Supervisor, and the State Store.
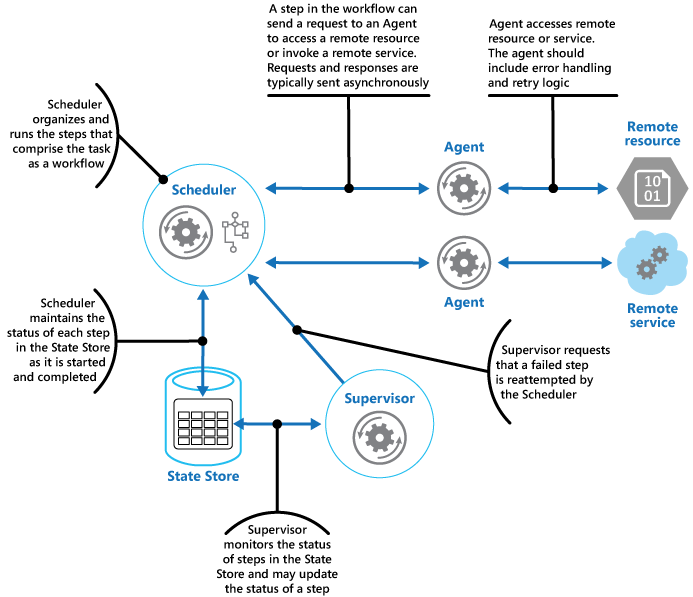
The actors in the Scheduler Agent Supervisor pattern
When an application wishes to run a task, it submits a request to the Scheduler. The Scheduler records initial state information about the task and its steps (for example, “step not yet started”) in the State Store and then commences performing the operations defined by the workflow. As the Scheduler starts each step, it updates the information about the state of that step in the State Store (for example, “step running”).
If a step references a remote service or resource, the Scheduler sends a message to the appropriate Agent. The message may contain the information that the Agent needs to pass to the service or access the resource, in addition to the Complete By time for the operation. If the Agent completes its operation successfully, it returns a response to the Scheduler. The Scheduler can then update the state information in the State Store (for example, “step completed”) and perform the next step. This process continues until the entire task is complete.
An Agent can implement any retry logic that is necessary to perform its work. However, if the Agent does not complete its work before the Complete By period expires the Scheduler will assume that the operation has failed. In this case, the Agent should stop its work and not attempt to return anything to the Scheduler (not even an error message), or attempt any form of recovery. The reason for this restriction is that, after a step has timed out or failed, another instance of the Agent may be scheduled to run the failing step (this process is described later).
If the Agent itself fails, the Scheduler will not receive a response. The pattern may not make a distinction between a step that has timed out and one that has genuinely failed.
If a step times out or fails, the State Store will contain a record that indicates that the step is running (“step running”), but the Complete By time will have passed. The Supervisor looks for steps such as this and attempts to recover them. One possible strategy is for the Supervisor to update the Complete By value to extend the time available to complete the step, and then send a message to the Scheduler identifying the step that has timed out . The Scheduler can then attempt to repeat this step. However, such a design requires the tasks to be idempotent.
It may be necessary for the Supervisor to prevent the same step from being retried if it continually fails or times out. To achieve this, the Supervisor could maintain a retry count for each step, along with the state information, in the State Store. If this count exceeds a predefined threshold the Supervisor can adopt a strategy such as waiting for an extended period before notifying the Scheduler that it should retry the step, in the expectation that the fault will be resolved during this period. Alternatively, the Supervisor can send a message to the Scheduler to request the entire task be undone by implementing a Compensating Transaction (this approach will depend on the Scheduler and Agents providing the information necessary to implement the compensating operations for each step that completed successfully).
If the Scheduler is restarted after a failure, or the workflow being performed by the Scheduler terminates unexpectedly, the Scheduler should be able to determine the status of any in-flight task that it was handling when it failed, and be prepared to resume this task from the point at which it failed. The implementation details of this process are likely to be system specific. If the task cannot be recovered, it may be necessary to undo the work already performed by the task. This may also require implementing a Compensating Transaction.
The key advantage of this pattern is that the system is resilient in the event of unexpected temporary or unrecoverable failures. The system can be constructed to be self-healing. For example, if an Agent or the Scheduler crashes, a new one can be started and the Supervisor can arrange for a task to be resumed. If the Supervisor fails, another instance can be started and can take over from where the failure occurred. If the Supervisor is scheduled to run periodically, a new instance may be automatically started after a predefined interval. The State Store may be replicated to achieve an even greater degree of resiliency.
Use this pattern when a process that runs in a distributed environment such as the cloud must be resilient to communications failure and/or operational failure.
This pattern might not be suitable for tasks that do not invoke remote services or access remote resources.
Akka uses actors which closely resemble the scheduler
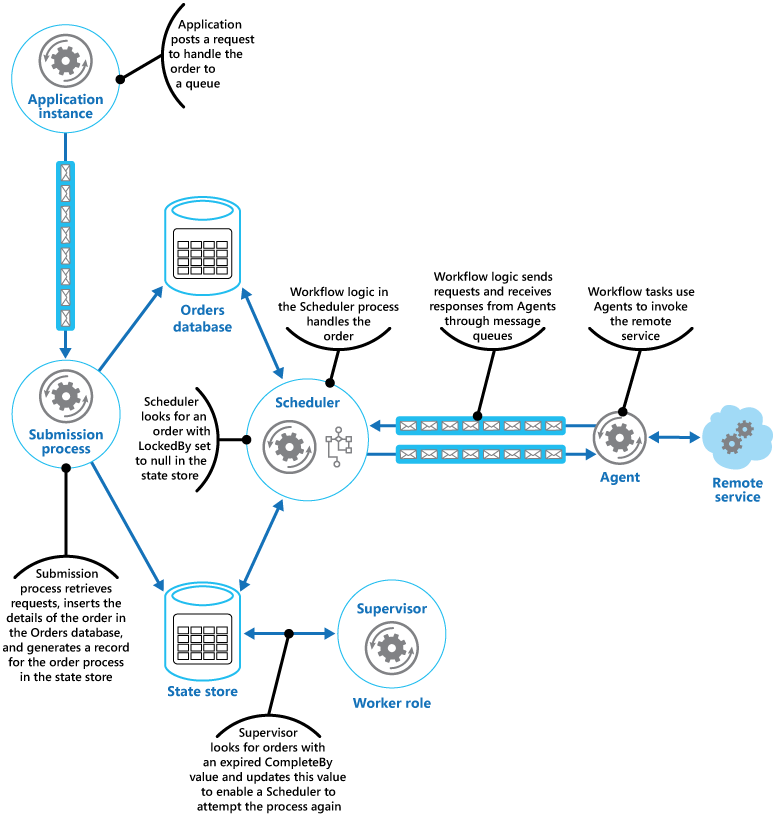
 Systems
Systems