Command and Query Responsibility Segregation (CQRS) Pattern
Context and Problem
In traditional data management systems, both commands (updates to the data) and queries (requests for data) are executed against the same set of entities in a single data repository. These entities may be a subset of the rows in one or more tables in a relational database such as SQL Server.
Typically, in these systems, all create, read, update, and delete (CRUD) operations are applied to the same representation of the entity. For example, a data transfer object (DTO) representing a customer is retrieved from the data store by the data access layer (DAL) and displayed on the screen. A user updates some fields of the DTO (perhaps through data binding) and the DTO is then saved back in the data store by the DAL. The same DTO is used for both the read and write operations, as shown below.
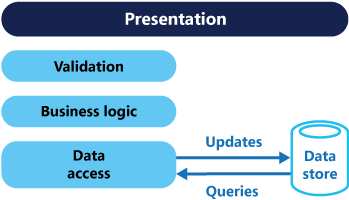
A traditional CRUD architecture
Traditional CRUD designs work well when there is only limited business logic applied to the data operations. Scaffold mechanisms provided by development tools can create data access code very quickly, which can then be customized as required.
However, the traditional CRUD approach has some disadvantages:
- It often means that there is a mismatch between the read and write representations of the data, such as additional columns or properties that must be updated correctly even though they are not required as part of an operation.
- It risks encountering data contention in a collaborative domain (where multiple actors operate in parallel on the same set of data) when records are locked in the data store, or update conflicts caused by concurrent updates when optimistic locking is used. These risks increase as the complexity and throughput of the system grows. In addition, the traditional approach can also have a negative effect on performance due to load on the data store and data access layer, and the complexity of queries required to retrieve information.
- It can make managing security and permissions more cumbersome because each entity is subject to both read and write operations, which might inadvertently expose data in the wrong context.
Solution
Command and Query Responsibility Segregation (CQRS) is a pattern that segregates the operations that read data (Queries) from the operations that update data (Commands) by using separate interfaces. This implies that the data models used for querying and updates are different. The models can then be isolated, as shown below, although this is not an absolute requirement.
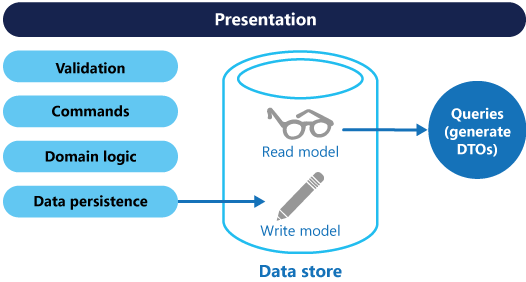
A basic CQRS architecture
Compared to the single model of the data (from which developers build their own conceptual models) that is inherent in CRUD-based systems, the use of separate query and update models for the data in CQRS-based systems considerably simplifies design and implementation. However, one disadvantage is that, unlike CRUD designs, CQRS code cannot automatically be generated by using scaffold mechanisms.
The query model for reading data and the update model for writing data may access the same physical store, perhaps by using SQL views or by generating projections on the fly. However, it is common to separate the data into different physical stores to maximize performance, scalability, and security; as shown below.
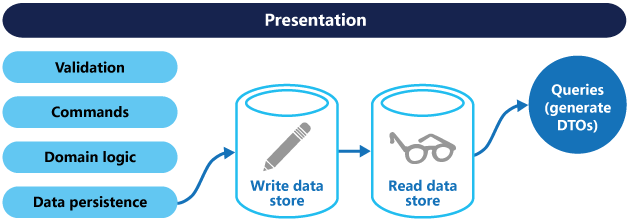
A CQRS architecture with separate read and write stores
The read store can be a read-only replica of the write store, or the read and write stores may have a different structure altogether. Using multiple read-only replicas of the read store can considerably increase query performance and application UI responsiveness, especially in distributed scenarios where read-only replicas are located close to the application instances. Some database systems, such as SQL Server, provide additional features such as failover replicas to maximize availability.
Separation of the read and write stores also allows each to be scaled appropriately to match the load. For example, read stores typically encounter a much higher load that write stores.
When the query/read model contains denormalized information, performance is maximized when reading data for each of the views in an application or when querying the data in the system.
When to Use this Pattern
This pattern is ideally suited to:
- Collaborative domains where multiple operations are performed in parallel on the same data. CQRS allows you to define commands with a sufficient granularity to minimize merge conflicts at the domain level (or any conflicts that do arise can be merged by the command), even when updating what appears to be the same type of data.
- Use with task-based user interfaces (where users are guided through a complex process as a series of steps), with complex domain models, and for teams already familiar with domain-driven design (DDD) techniques. The write model has a full command-processing stack with business logic, input validation, and business validation to ensure that everything is always consistent for each of the aggregates (each cluster of associated objects that are treated as a unit for the purpose of data changes) in the write model. The read model has no business logic or validation stack and just returns a DTO for use in a view model. The read model is eventually consistent with the write model.
- Scenarios where performance of data reads must be fine-tuned separately from performance of data writes, especially when the read/write ratio is very high, and when horizontal scaling is required. For example, in many systems the number of read operations is orders of magnitude greater that the number of write operations. To accommodate this, consider scaling out the read model, but running the write model on only one or a few instances. A small number of write model instances also helps to minimize the occurrence of merge conflicts.
- Scenarios where one team of developers can focus on the complex domain model that is part of the write model, and another less experienced team can focus on the read model and the user interfaces.
- Scenarios where the system is expected to evolve over time and may contain multiple versions of the model, or where business rules change regularly.
- Integration with other systems, especially in combination with Event Sourcing, where the temporal failure of one subsystem should not affect the availability of the others.
This pattern might not be suitable in the following situations:
- Where the domain or the business rules are simple.
- Where a simple CRUD-style user interface and the related data access operations are sufficient.
- For implementation across the whole system. There are specific components of an overall data management scenario where CQRS can be useful, but it can add considerable and often unnecessary complexity where it is not actually required.
Event Sourcing and CQRS
The CQRS pattern is often used in conjunction with the Event Sourcing pattern. CQRS-based systems use separate read and write data models, each tailored to relevant tasks and often located in physically separate stores. When used with Event Sourcing, the store of events is the write model, and this is the authoritative source of information. The read model of a CQRS-based system provides materialized views of the data, typically as highly denormalized views. These views are tailored to the interfaces and display requirements of the application, which helps to maximize both display and query performance.
Using the stream of events as the write store, rather than the actual data at a point in time, avoids update conflicts on a single aggregate and maximizes performance and scalability. The events can be used to asynchronously generate materialized views of the data that are used to populate the read store.
Because the event store is the authoritative source of information, it is possible to delete the materialized views and replay all past events to create a new representation of the current state when the system evolves, or when the read model must change. The materialized views are effectively a durable read-only cache of the data.
When using CQRS combined with the Event Sourcing pattern, consider the following:
- As with any system where the write and read stores are separate, systems based on this pattern are only eventually consistent. There will be some delay between the event being generated and the data store that holds the results of operations initiated by these events being updated.
- The pattern introduces additional complexity because code must be created to initiate and handle events, and assemble or update the appropriate views or objects required by queries or a read model. The inherent complexity of the CQRS pattern when used in conjunction with Event Sourcing can make a successful implementation more difficult, and requires relearning of some concepts and a different approach to designing systems. However, Event Sourcing can make it easier to model the domain, and makes it easier to rebuild views or create new ones because the intent of the changes in the data is preserved.
- Generating materialized views for use in the read model or projections of the data by replaying and handling the events for specific entities or collections of entities may require considerable processing time and resource usage, especially if it requires summation or analysis of values over long time periods, because all the associated events may need to be examined. This may be partially resolved by implementing snapshots of the data at scheduled intervals, such as a total count of the number of a specific action that have occurred, or the current state of an entity.
 Systems
Systems