Referenced from https://www.rabbitmq.com documentation
Given a cluster of RabbitMQ nodes, we want to achieve effective load-balancing.
First, let’s look at the feature at the core of RabbitMQ – the Queue itself.
RabbitMQ Queues are singular structures that do not exist on more than one Node. Let’s say that you have a load-balanced, HA (Highly Available - Queue mirroring across all nodes in contrast to the default single node) RabbitMQ cluster as follows:
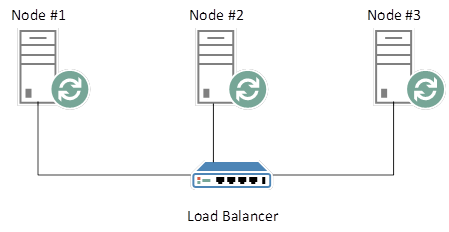
RabbitMQ Cluster with Load Balancer
Node #2 does not return a heartbeat, and is considered de-clustered
This is standard HA behaviour in RabbitMQ. Let’s look at the default scenario now, where all 3 nodes are alive and well, and the “NewQueue” instance on Node #2 is still master.
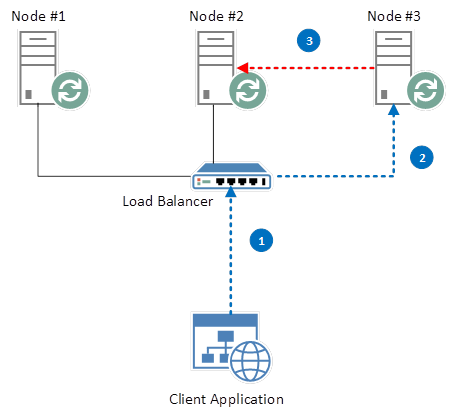
RabbitMQ Cluster Exhibiting Extra Network-hop
Unfortunately for us, this means that we suffer an extra, unnecessary network hop in order to reach our intended Queue. This may not seem a major issue, but consider that in the above example, with 3 nodes and an evenly-balanced Load Balancer, we are going to incur that extra network hop on approximately 66% of requests. Only one in every three requests (assuming that in any grouping of three unique requests we are directed to a different node) will result in our request being directed to the correct node.
Does this mean that we can’t implement round robin load-balancing?
No, but if we do, it will result in a less than optimal solution.”
So, what’s the alternative?
Well, in order to ensure that each request is routed to the correct node, we have two choices:
Both solutions immediately introduce problems. In the first instance, our client application must be aware of all nodes in our RabbitMQ cluster, and must also know where each master Queue resides. If a Node goes down, how will our application know? Not to mention that this design breaks the Single Responsibility principle, and increases the level of coupling in the application.
The second solution offers a design in which our Queues are not linked to single nodes. Based on our “NewQueue” example, we would not simply instantiate a new Queue on a single node. Instead, in a 3-node scenario, we might instantiate 3 Queues; “NewQueue1”, “NewQueue2” and “NewQueue3”, where each Queue is instantiated on a separate node.
The second solution offers a design in which our Queues are not linked to single Nodes. Based on our “NewQueue” example, we would not simply instantiate a new Queue on a single Node. Instead, in a 3-node scenario, we might instantiate 3 Queues; “NewQueue1”, “NewQueue2” and “NewQueue3”, where each Queue is instantiated on a separate Node:
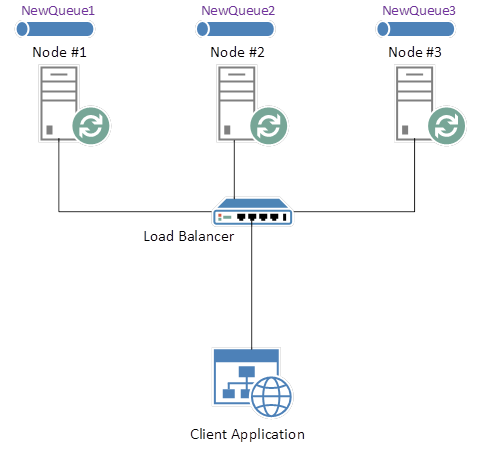
RabbitMQ Cluster with Separate Queues
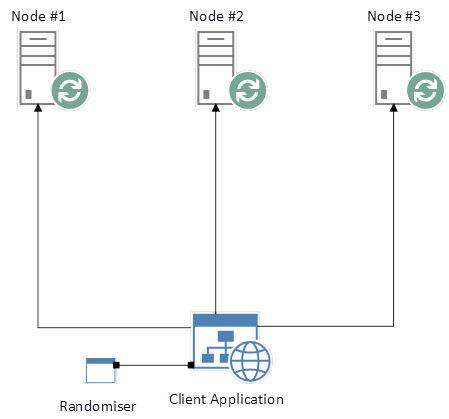
Our client application can now implement, for example, a simple randomising function that selects one of the above Queues and explicitly connects to it. In a web-based application, given 3 separate HTTP requests, each request would target one of the above Queues, and no Queue would feature more than once across all 3 requests. Now we’ve achieved a reasonable balance of load across our cluster, without the use of a traditional Load Balancer.
RabbitMQ Cluster with Randomiser
But we’re still faced with the same problem; our client application needs to know where our Queues reside. So let’s look at advancing the solution further, so that we can avoid this shortcoming.
Firstly, we need to provide mapping metadata that describes our RabbitMQ infrastructure. Specifically, where Queues reside. This should be a resilient data-source such as a database or cache, as opposed to something like a flat file, because multiple sources (2, at least) may access this data concurrently.
Now introduce an always-on service that polls RabbitMQ, determining whether or not nodes are alive. New Queues should also be registered with this service, and it should keep an up-to-date registry, providing metadata about Nodes and their Queues:
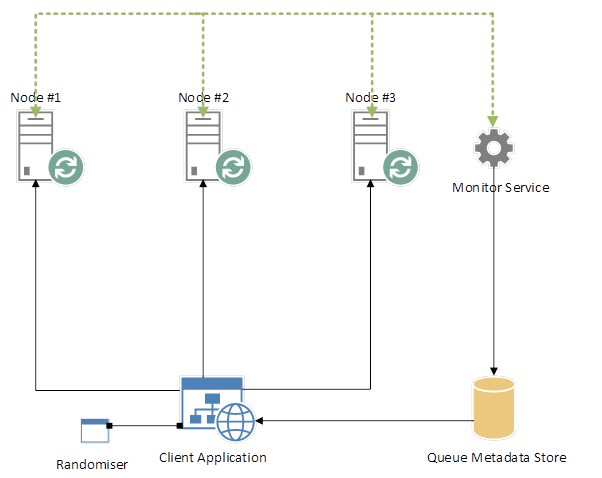
RabbitMQ Cluster with Monitor Service
Our client application, on initial load, should poll this service and retrieve RabbitMQ metadata, which should then be retained for incoming requests. Should a request fail due to the fact that a Node becomes compromised, the client application can poll the Queue Metadata Store, return up-to-date RabbitMQ metadata, and re-route the message to a working Node.
 Systems
Systems